給定一個訓練數據集,對於新的輸入數據,我們從數據集裡找到與新數據最相鄰的k個數據,並且找出k個數據多類屬於某個類,就把新的數據也歸納到該類中。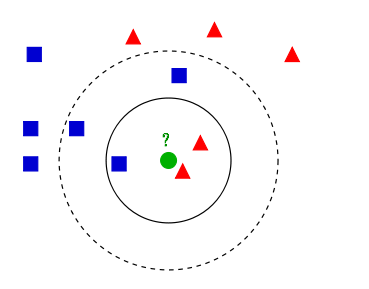
如上圖所示,圖中有兩個不同類的樣本數據分別用藍色矩形和紅色三角形表示,而圖正中間的綠色圓形是待分類的新數據。
根據k近鄰算法分類:
如果K=3,最近的三個點是2個紅色三角形,1個藍色矩形,因此根據多數決,綠色的待分類點屬於紅色的三角形類。
如果K=5,最近的5個點是2個紅色三角形,3個藍色矩形,因此新數據屬於藍色矩形一類。
至此我們已經掌握了K近鄰算法的核心觀念。
K近鄰算法在真實問題的應用上,有幾個必須要解決的,首先是K怎麼得到的,當K為多少時分類的效果最好。第二是怎麼計算數據間的距離呢?我們要怎麼得到樣本數據集裡的最近鄰?


 iThome鐵人賽
iThome鐵人賽